[CUDA 5.5] CUDA 메모리 성능 최적화
![[CUDA 5.5] CUDA 메모리 성능 최적화](/assets/images/cuda-memory-optimization/title.png)
Summary
사진이나 세부적인 내용은 지금과 다를 수 있습니다.
CUDA 메모리는 CPU와 비교하면 무척이나 빠른 메모리 액세스 속도를 제공하지만, 최적화된 성능을 발휘하기 위해서는 여러 조건들을 충족시켜야 합니다. CUDA는 수백, 수천 개의 코어에서 DRAM이나 캐시에 있는 데이터를 동시에 읽고, 쓰기 때문에 데이터 병목 현상(bottleneck)이 발생하게 됩니다. 이러한 제약 조건들도 새로운 그래픽 카드가 출시되면서 점차 개선되고 있지만, CUDA 어플리케이션의 성능을 향상시키기 위해서는 이러한 병목 현상을 피하고 이상적인 병렬화를 구현할 필요가 있습니다.
글로벌 메모리 액세스 결합 (Coalescing)
CUDA 프로그램에서 구현하는 솔루션과 데이터의 형식에 따라 다양한 글로벌 메모리 액세스 패턴이 나타나게 됩니다. NVIDIA 그래픽 카드의 메모리 전송은 한 번에 512bit를 읽어올 때 최대의 성능을 발휘한다고 알려져 있습니다. 글로벌 메모리를 읽어올 때 최대 bandwidth를 사용할 수 있는 조건이 있는데, 이것을 메모리 결합(Coalescing) 조건이라고 합니다. CUDA에서 결합 조건을 충족할 때와 하지 못했을 때 그래픽 카드의 종류에 따라 최대 10배의 성능 차이가 발생합니다.
GeForce 200 시리즈 이후로 글로벌 메모리 액세스 결합 전송 조건이 많이 완화되고, 자동화됨에 따라 이전 시리즈의 그래픽 카드보다 쉽게 개선된 성능을 보입니다. 하지만 가끔 비결합 전송 상태로 동작하여 낮은 성능을 나타낼 때도 있기 때문에 프로그램을 실행하면서 성능을 확인하여 결합 전송이 자동으로 이루어지는지를 확인할 필요가 있습니다.
공유 메모리 뱅크 충돌 (Bank Conflict)
공유 메모리는 GPU 프로세서 내부에 장착되어 있어 제대로 사용하면 빠른 속도로 데이터를 처리할 수 있는 CUDA의 큰 장점 중 하나입니다. 공유 메모리의 속도를 저하하는 요인으로는 공유 메모리를 구성하는 메모리 뱅크의 액세스 충돌(Bank Conflic)이 있습니다. 메모리 뱅크(Memory Bank)는 각 뱅크마다 한 번의 GPU 사이클에 한 번 액세스 할 수 있으며, 뱅크의 개수만큼의 스레드가 병렬로 모든 뱅크에 동시에 액세스 할 때 가장 큰 효율을 얻을 수 있습니다.
간단한 섬영르 위해 16KB 공유 메모리와 4개의 뱅크가 있고, 각각의 뱅크는 1KB의 메모리로 이루어져 있다고 가정합시다. 또, 뱅크 0번부터 4byte씩 메모리가 배치되어 16byte 블록이 하나의 열을 이루는 형식이라고 가정하겠습니다.
뱅크 충돌이 없는 공유 메모리 액세스
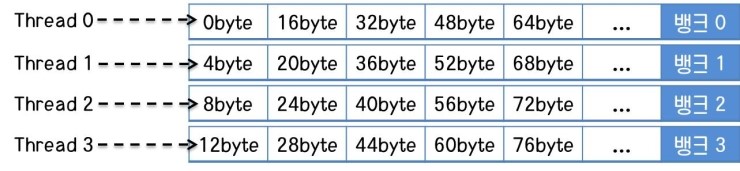
위 그림은 뱅크 충돌이 없는 공유 메모리 액세스를 나타냅니다. 공유 메모리에는 글로벌 메모리와 같은 시작 address나 결합 전송 조건은 없지만, 한 스레드 당 하나의 뱅크에 액세스 할 수 있다는 제약이 있습니다.
그림에서는 4개의 스레드가 각각 하나의 뱅크에 액세스하여 뱅크 충돌이 없는 이상적인 패턴을 나타내고 있습니다. 공유 메모리는 글로벌 메모리와 같은 액세스 시작 위치 또는 오름차순 정렬 조건이 없기 때문에 랜덤 액세스에 대해서도 같은 뱅크 액세스만 없으면 효괒거으로 동작하게 됩니다.
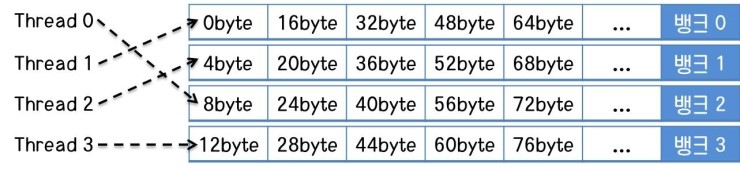
즉, 위 그림과 같이 스레드가 어지럽게 공유 메모리에 액세스하더라도 같은 뱅크끼리 겹치는 스레드가 없다면 공유 메모리는 효과적으로 동작합니다.
2-way 뱅크 충돌
만일 모든 스레드가 한 번에 공유 메모리를 읽거나 쓸 때, 2개의 스레드가 하나의 뱅크에 액세스하려고 하면 뱅크 충돌이 발생하게 됩니다. 2번의 뱅크 충돌이 발생하는 것을 2-way 뱅크 충돌이라고 하는데, 2-way 뱅크 충돌이 발생하면 GPU가 2번의 사이클에 나누어 공유 메모리를 차례로 가져오게 되고, 결국 효율이 절반으로 떨어지게 됩니다.
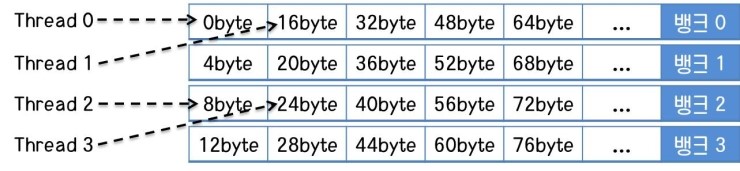
위 그림은 모든 스레드가 2개씩 하나의 뱅크에 액세스하고 있는 2-way 뱅크 충돌을 나타냅니다. 비슷한 예로 4-way 뱅크 충돌 또한 존재하는데, 4-way 뱅크 충돌이 일어나게 되면 효율은 1/4로 떨어지게 됩니다.
CUDA에서 항상 모든 스레드가 2개씩 하나의 뱅크에 액세스해야만이 2-way 뱅크 충돌이 되는 것은 아닙니다. 모든 스레드 중에서 2개의 스레드만 같은 뱅크에 액세스하더라도 결국 GPU는 2번의 사이클에 나누어 공유 메모리에 접근해야 하기 때문에 효율이 절반으로 떨어지는 것은 똑같습니다.
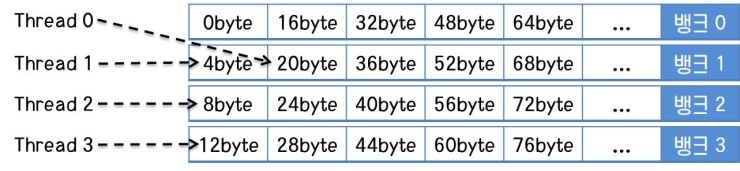
위 그림처럼 모든 스레드가 정렬되어 공유 메모리에 액세스하고 있지만, 스레드 0과 스레드 1이 뱅크 1에 동시에 액세스하고 있는 경우 또한 2-way 뱅크 충돌입니다. 이렇게 프로그램이 구현되어 있으면 아무리 다른 스레드들이 정렬되어 있다고 하여도 전체 효율은 절반으로 떨어집니다. 이것은 워프 단위로 실행하고 워프의 절반 단위로 메모리에 액세스하는 CUDA thread의 특징 때문입니다.
16-way 뱅크 충돌
16-way 뱅크 충돌은 1차원으로 구성된 스레드-블록(thread-block) 구조에서는 잘 발생하지 않습니다. 하지만 2차원 스레드-블록 구조로 작업을 분할할 때 스레드 인덱스 처리가 제대로 되지 않으면 발생할 수 있습니다. 16-way 뱅크 충돌이 일어나면 2-way 뱅크 충돌이나 4-way 뱅크 충돌과 마찬가지로 각 스레드가 하나의 뱅크에 차례로 액세스하기 때문에 효율이 1/16으로 떨어지게 됩니다.
16-way 뱅크 충돌이 주로 2차원 스레드-블록 구조에서 발생하는 이유는 1차원의 경우 일반적으로 행 방향으로 인덱스를 진행하여 액세스하지만, 2차원에서는 열 방향으로도 인덱스를 진행하는 경우가 생기기 때문입니다.
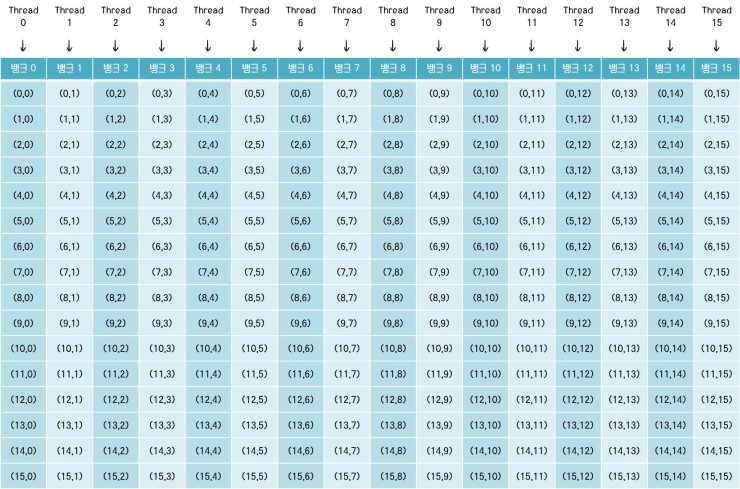
위 그림과 같이 행 방향으로만 인덱스를 진행할 경우 뱅크 충돌이 발생하지 않고 정상적으로 동작하게 됩니다. 하지만 열 방향으로 인덱스를 진행하면 아래와 같이 뱅크 충돌이 발생할 수 있습니다.
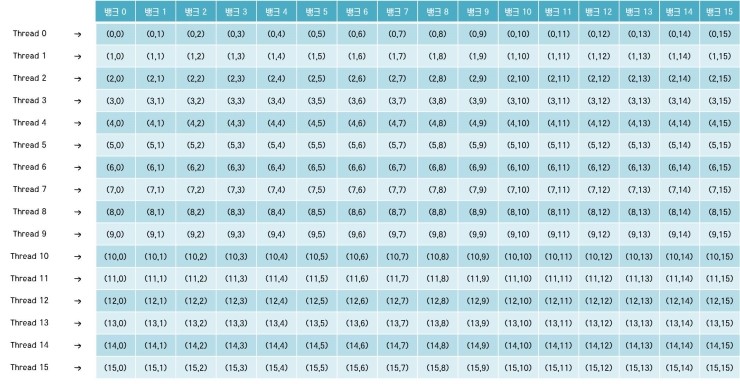
위 그림은 공유 메모리의 뱅크 0에 16개의 스레드가 모두 액세스하여 16-way 뱅크 충돌이 발생하게 되는 상황을 나타냅니다. 이와 같은 뱅크 충돌을 피하기 위해서는 알고리즘을 수정하기 보다는 메모리 할당 공간을 수정하는 것이 좋은 방법입니다.
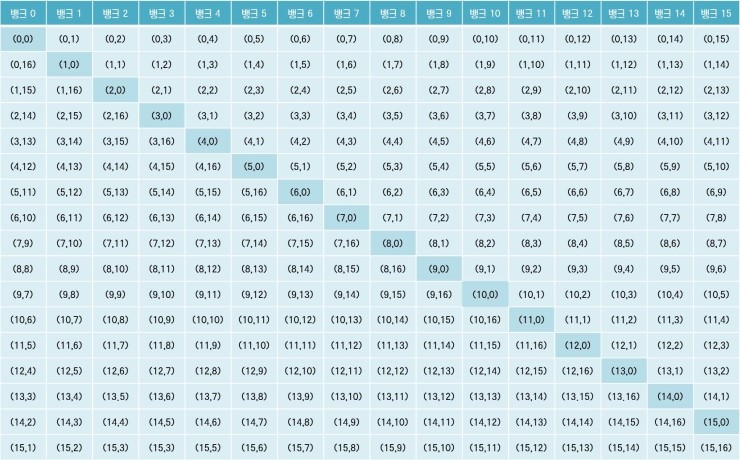
위 그림은 공유 메모리에 16x17의 배열이 물리적으로 할당된 형태를 나타냅니다. 이와 같은 방법을 메모리 패딩(Memory Padding)이라고 합니다. 위와 같이 공유 메모리를 16x17로 하면 행 방향과 열 방향의 메모리가 동일한 뱅크에 할당되지 않습니다. 약간의 공간을 더 소비함으로써 16-way 뱅크 충돌을 피하고, 뱅크 충돌이 발생했을 때보다 16배의 액세스 속도를 얻을 수 있습니다.
고정 메모리 (Pinned Memory)
페이지 락 메모리(Page Lock Memory) 또는 고정 메모리(Pinned Memory)라 불리는 시스템 메모리는 가상 메모리(Virtual Memory) 기술과 관련이 있습니다. 가상 메모리는 컴퓨터에 장착된 RAM의 용량에 한계가 있어 충분하지 않기 때문에 발생하는 메모리 부족 문제를 해결하기 위한 방법으로 개발된 것입니다. 가상 메모리는 컴퓨터와 운영체제에 의해 제어되며 RAM의 부족한 용량을 HDD의 도움을 받아 해결합니다. 운영체제 시스템에 RAM과 HDD의 공간을 이용하여 가상으로 큰 메모리 공간을 페이지 단위로 분할하여 제공하는 것입니다.
CUDA 프로그램의 약점 중 하나는 GPU로 계산하기 전에 입력 데이터를 host에서 device로 복사하고, 또 계산된 결과를 device에서 host로 복사하는 과정이 추가되는 것입ㄴ디ㅏ. 이 시간은 기존의 프로그램과 비교했을 때 추가적인 부하로 작용하며, 병목 현상(bottleneck)이 발생할 가능성이 높습니다. 때문에 이 시간을 줄이고자 CUDA 프로그램을 구현할 때 여러 가지 방법을 사용하게 됩니다.
그 중 하나가 바로 가상 메모리 기술의 일부를 제한하고 물리적인 RAM 공간만을 사용하는 것입니다. 가상 메모리를 이용하면 메모리를 사용하기 위해 HDD와 RAM 공간의 페이지 치환이 일어나게 되는데, 이 시간을 줄이고 물리적인 RAM에서 device로 복사하는 것입니다. 이렇게 페이지 치환이 되지 않는 메모리를 페이지 락 메모리(Page Lock Memory) 또는 고정 메모리(Pinned Memory)라고 부르는데, 이는 RAM 공간에만 상주하는 메모리를 의미합니다. 고정 메모리를 사용하면 일반적인 힙(Heap) 메모리 할당 방법보다 약 10~50%의 전송 속도가 향상됩니다. 또 CUDA에서 스트림(Stream, 비동기 함수)를 사용하기 위해서는 고정 메모리를 이용해야만 합니다.
고정 메모리는 CUDA API 함수 호출을 통해 사용할 수 있습니다. 하지만 고정 메모리는 항상 물리적 RAM 공간에 상주하기 때문에 고정 메모리를 너무 많이 사용할 경우 컴퓨터의 가상 메모리가 원활하게 작동하기 어려워 메모리 성능과 전체 시스템의 성능 저하를 가져올 수 있다는 단점이 있습니다.
제로 복사 (Zero-copy)
제로 복사(Zero-copy 혹은 MApped Memory) 기능은 단어 뜻 그대로 복사를 하지 않는다는 의미입니다. 대부분의 CUDA 프로그램은 GPU를 사용하기 위해 입력 데이터를 host에서 device로 복사하고, 그 데이터를 처리하여 출력 데이터를 device에서 host로 복사합니다. 이는 데이터 읽기와 계산, 쓰기의 과정이 차례로 실행되며 데이터 전송 시 사용되는 PCI 버스를 한 방향만 사용하게 합니다.
제로 복사는 GPU가 host에 할당된 고정 메모리 영역에 바로 액세스하여 데이터를 읽고 쓰는 작업을 말합니다. PCI 버스를 이용하여 데이터를 전송하는 것은 동일하기 때문에 전송 속도가 빨라지는 것은 아니지만, 메모리에서 읽어들인 데이터를 계산하고 결과값을 메모리에 쓰면 비동기로 양방향 PCI 전송이 진행되기 때문에 그만큼의 성능 향상을 얻을 수 있습니다. 이 방법은 통상적으로 1.5배에서 2배 가량의 성능 향상 효과가 있다고 알려져 있습니다.
하지만 이런 성능 향상 효과를 얻으려고 맵드 메모리(Mapped Memory)를 사용할 때 글로벌 메모리의 결합 전송(Coalescing)과 동일한 조건을 커널에서 충족시켜야 한다는 제약이 있습니다. 만일 커널에서 작은 크기의 데이터를 많은 횟수로 맵드 메모리에 액세스하게 되면 통상적인 데이터 전송보다 오히려 성능이 떨어지는 효과가 나타납니다.
제로 복사 기능은 GeForce 200 시리즈 이후 계열 GPU부터 지원하며, host 측의 고정 메모리(Pinned System Memory)에 직접 읽고 쓰게 됩니다. CUDA API 함수를 이용하여 맵드 메모리를 할당하는 방법으로 제로 복사를 사용할 수 있습니다. host에 메모리를 할당하고, device 메모리 영역에서 host 측 메모리로 바로 사용할 포인터를 지정해주는 방법으로 사용합니다.
포터블 고정 메모리 (Portable Pinned Memory)
고정된 메모리를 이용한 제로 복사는 싱글 스레드 영역에서 유효합니다. 하나의 GPU로 구성된 PC에서는 큰 불편함 없이 고정 메모리를 사용할 수 있지만, 복수의 GPU로 수정된 PC에서는 문제가 생길 수 있습니다. 동시에 2개 이상의 GPU를 구동시키려면 두 개 이상의 host thread를 생성하여 처리하게 되는데, 이 때 하나의 스레드에서 생성한 고정 메모리는 다른 스레드에서 사용할 수 없게 됩니다. 이러면 한정된 시스템 자원인 고정 메모리를 각각의 스레드에서 생성하여 자원을 낭비하는 결과를 낳게 됩니다.
이러한 자원 낭비를 피하고자 사용하는 방법이 바로 포터블 고정 메모리(Portable Pinned Memory)입니다. 포터블 고정 메모리를 사용하기 위해서는 CUDA API 함수에서 옵션을 바꾸어 주는 방법으로 사용할 수 있습니다.
이것으로 CUDA 메모리 성능 최적화 기법에 대한 소개가 끝났습니다. 메모리 성능은 CUDA 프로그램의 성능과 직결된 문제인만큼 다양한 관점에서 최적화 방법을 모색해야 할 것입니다.