[CUDA 5.0] CUDA syntax를 이용하여 device 정보 불러오기
![[CUDA 5.0] CUDA syntax를 이용하여 device 정보 불러오기](/assets/images/cuda-syntax-device/title.png)
사진이나 세부적인 내용은 지금과 다를 수 있습니다.
본격적인 CUDA 코딩에 앞서 CUDA syntax를 이용하여 device의 정보를 불러오는 방법에 대해 소개하려고 합니다. 여기서 말하는 device란 CUDA acceleration(CUDA 가속)을 지원하는 GPU를 뜻합니다. 아래의 코드는 CUDA syntax를 이용하여 device의 정보를 불러와 출력하는 내용입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
int main() {
int i;
cudaDeviceProp prop;
int count;
cudaGetDeviceCount(&count);
for (i = 0 ; i < count ; i++) {
cudaGetDeviceProperties(&prop, i);
printf("-- %d번째 디바이스 --\n", i+1);
printf(" (1) 장치 이름 : %s\n", prop.name);
printf(" (2) Clock Rate : %d\n", prop.clockRate);
printf(" (3) 전역 메모리 용량 : %ld\n", prop.totalGlobalMem);
printf(" (4) 상수 메모리 용량 : %ld\n", prop.totalConstMem);
printf(" (5) Register per block : %d\n", prop.regsPerBlock);
printf(" (6) Max Grid Size : %d\n", prop.maxGridSize);
printf(" (7) Max Thread Dimension : %d\n", prop.maxThreadsDim);
printf(" (8) Max Thread per block : %d\n", prop.maxThreadsPerBlock);
}
return 0;
}
CUDA는 cudaDeviceProp이라는 구조체 형식에 device들의 정보를 저장하게 됩니다. 이를 이용하면 device의 다양한 정보를 불러올 수 있습니다. 아래는 위 코드를 실행시킨 결과입니다.
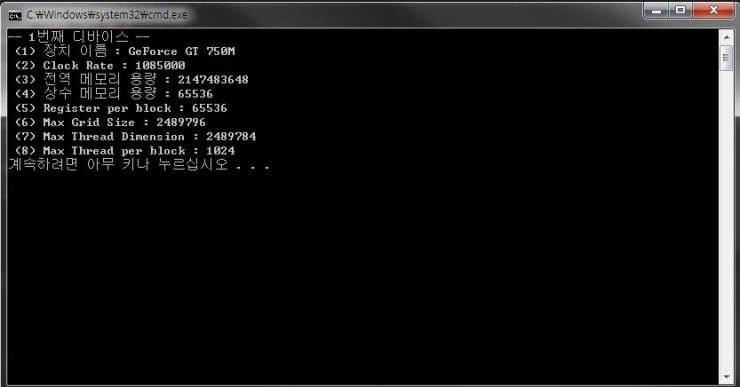
출력된 결과를 살펴보면, GeForce GT 750M이라는 하나의 device를 사용 중이며, clock rate나 메모리 용량이 얼마인지 알 수 있습니다. cudaDeviceProp은 이외에도 다양한 정보를 제공합니다. 이러한 데이터를 잘 활용하면 효과적인 CUDA 코딩을 할 수 있을 것입니다.
그러면 위 코드를 자세히 살펴봅시다.
1
cudaDeviceProp prop;
Device property의 출력을 위해 구조체를 생성한 것입니다. 위에서 잠깐 언급했듯이 CUDA는 device의 정보를 구조체 형식에 저장합니다. cudaDeviceProp 구조체는 driver_types.h 파일에 선언되어 있으며, 이러한 header file들은 CUDA project를 생성하면 외부 종속성 폴더에 추가되도록 되어 있습니다.
아래는 cudaDeviceProp 구조체의 선언 부분입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
/**
* CUDA device properties
*/
struct __device_builtin__ cudaDeviceProp
{
char name[256]; /**< ASCII string identifying device */
size_t totalGlobalMem; /**< Global memory available on device in bytes */
size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
int regsPerBlock; /**< 32-bit registers available per block */
int warpSize; /**< Warp size in threads */
size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */
int maxThreadsPerBlock; /**< Maximum number of threads per block */
int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */
int maxGridSize[3]; /**< Maximum size of each dimension of a grid */
int clockRate; /**< Clock frequency in kilohertz */
size_t totalConstMem; /**< Constant memory available on device in bytes */
int major; /**< Major compute capability */
int minor; /**< Minor compute capability */
size_t textureAlignment; /**< Alignment requirement for textures */
size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */
int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */
int multiProcessorCount; /**< Number of multiprocessors on device */
int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */
int integrated; /**< Device is integrated as opposed to discrete */
int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */
int computeMode; /**< Compute mode (See ::cudaComputeMode) */
int maxTexture1D; /**< Maximum 1D texture size */
int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */
int maxTexture1DLinear; /**< Maximum size for 1D textures bound to linear memory */
int maxTexture2D[2]; /**< Maximum 2D texture dimensions */
int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */
int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */
int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */
int maxTexture3D[3]; /**< Maximum 3D texture dimensions */
int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */
int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */
int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */
int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */
int maxSurface1D; /**< Maximum 1D surface size */
int maxSurface2D[2]; /**< Maximum 2D surface dimensions */
int maxSurface3D[3]; /**< Maximum 3D surface dimensions */
int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */
int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */
int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */
int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */
size_t surfaceAlignment; /**< Alignment requirements for surfaces */
int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */
int ECCEnabled; /**< Device has ECC support enabled */
int pciBusID; /**< PCI bus ID of the device */
int pciDeviceID; /**< PCI device ID of the device */
int pciDomainID; /**< PCI domain ID of the device */
int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */
int asyncEngineCount; /**< Number of asynchronous engines */
int unifiedAddressing; /**< Device shares a unified address space with the host */
int memoryClockRate; /**< Peak memory clock frequency in kilohertz */
int memoryBusWidth; /**< Global memory bus width in bits */
int l2CacheSize; /**< Size of L2 cache in bytes */
int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */
};
위와 같이 선언되어 있는데, 각각 어떤 것을 의미하는지는 각 항목마다 설명이 주석처리 되어 있으므로 자세한 설명은 하지 않겠습니다. 앞서 출력해 보았던 내용 이외에도 엄청나게 많은 정보들을 저장하고 있지만, 가장 많이 쓰이게 될 몇 가지 정보들만 출력해 보았습니다.
1
2
int count;
cudaGetDeviceCount(&count);
device 장치의 개수를 획득하는 함수입니다. int 형 변수인 count를 만들고, 그것의 주소값을 argument로 넘겨주게 됩니다. cudaGetDeviceCount 함수는 cuda_runtime_api.h에 다음과 같이 정의되어 있습니다.
1
extern __host__ __cudart_builtin__ cudaError_t CUDARTAPI cudaGetDeviceCount(int *count);
parameter로 count의 포인터를 넘겨 받기 때문에 호출 시 argument의 사용에 주의해 주셔야 합니다. 함수의 이름에서 알 수 있다시피 count 변수에는 device의 개수 값이 들어갑니다.
CUDA 뿐만이 아니라 다른 언어나 tool을 공부할 때에도 마찬가지로, 어떤 함수를 사용할 때 그것이 어떻게 정의되어 있는지 내부를 공부하는 것은 무척이나 많은 도움이 됩니다. 특히나 CUDA는 C 기반으로 짜여져 있는데다 주석도 잘 달려 있어 공부하기 편리합니다.
이렇게 CUDA syntax를 이용하여 device의 정보를 출력하는 방법에 대해 알아보았습니다. 이후 포스팅에서 CUDA 병렬 프로그래밍에 대해 더 자세히 알아보도록 하겠습니다.